OCR(Optical Character Recognition,光学字符识别)是一种将图片、PDF文件或扫描件中的文字转换成可编辑文本的技术,随着科技的发展,越来越多的OCR软件应运而生,为用户提供了便捷的文字识别服务,本文将详细介绍如何使用OCR文字识别软件。
1、选择合适的OCR软件
市面上有许多OCR软件供用户选择,如Adobe Acrobat、ABBYY FineReader、百度OCR等,用户可以根据自己的需求和操作系统选择合适的软件。

2、安装并打开OCR软件
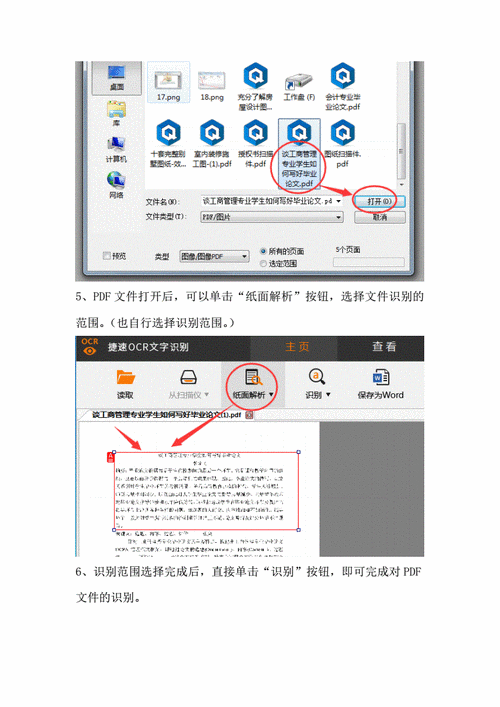
下载并安装所选的OCR软件,然后打开软件,OCR软件的界面会有一个“打开”或“导入”按钮,点击该按钮,选择需要识别的图片、PDF文件或扫描件。
3、设置识别参数
在导入文件后,用户需要设置识别参数,这些参数包括识别语言、识别格式等,如果需要识别中文,可以选择“简体中文”或“繁体中文”;如果需要将识别结果保存为Word文档,可以选择“Microsoft Word”。
4、开始识别
设置好识别参数后,点击“开始识别”或“开始处理”按钮,软件会自动进行文字识别,识别过程可能需要一段时间,具体取决于文件的大小和复杂程度。
5、查看识别结果
识别完成后,用户可以在软件界面查看识别结果,OCR软件会以预览的形式展示识别结果,用户可以对识别结果进行编辑和修改,如果识别结果有误,用户可以手动修改错误部分。
6、保存识别结果
确认识别结果无误后,用户可以将识别结果保存为可编辑的文本文件,OCR软件支持多种文件格式,如TXT、DOC、PDF等,用户可以根据自己的需求选择合适的文件格式。
7、导出识别结果
除了保存为本地文件外,用户还可以将识别结果导出到其他应用程序,用户可以将识别结果导出到Microsoft Word、Excel等办公软件中,方便后续编辑和处理。
使用OCR文字识别软件可以大大提高工作效率,节省时间,用户只需按照上述步骤操作,即可轻松完成文字识别任务,不过,需要注意的是,不同的OCR软件操作方法可能略有不同,用户在使用时应参考具体的软件说明。